I just ran into a problem with Pentaho Data Integration, and I figured it may save others some time if I document it here.
The case is very straightforward: read a fairly small XML document directly from a URL, and parse out interesting data using the
 Get data from XML step.
Get data from XML step.
Typically, this steps works quite well for me. But I just ran into a case where it doesn't work quite as expected. I ran into an error when I tried it on this URL:
http://api.worldbank.org/en/countries?page=1If you follow the URL you'll find it returns a normal looking document:
<?xml version="1.0" encoding="utf-8"?>
<wb:countries page="1" pages="6" per_page="50" total="260" xmlns:wb="http://www.worldbank.org">
<wb:country id="ABW">
<wb:iso2Code>AW</wb:iso2Code>
<wb:name>Aruba</wb:name>
<wb:region id="LCN">Latin America & Caribbean (all income levels)</wb:region>
<wb:adminregion id="" />
<wb:incomeLevel id="NOC">High income: nonOECD</wb:incomeLevel>
<wb:lendingType id="LNX">Not classified</wb:lendingType>
<wb:capitalCity>Oranjestad</wb:capitalCity>
<wb:longitude>-70.0167</wb:longitude>
<wb:latitude>12.5167</wb:latitude>
</wb:country>
...
</wb:countries>
The error: Content is not allowed in prolog
The error I got was:Content is not allowed in prolog.You can encounter this error in any context where the step tries to retrieve the document from the URL, for example when you hit the "Get XPAth nodes" or "Preview" buttons, as well as when you're actually running the step.
Using the w3c XML validator
The error message indicates that the XML document is in some way not valid. So I ran the URL through the w3c validator:http://validator.w3.org/check?uri=http%3A%2F%2Fapi.worldbank.org%2Fen%2Fcountries%3Fpage%3D1&charset=%28detect+automatically%29&doctype=Inline&group=0Interestingly, this indicated that the document is valid XML.
A rather dismal workaround
Then I tried a few things in kettle in an attempt to work around it. I won't bother you with everything I tried. Eventually, I did find a viable work-around: By retrieving the document with the HTTP Client step, and then saving that to file using a simple
HTTP Client step, and then saving that to file using a simple  Text file output step (omitting the header, separators, and quotes), I could then successfully open and parse that file with the "Get data from XML" step (from within a second transformation).
This was of course a bit annoying since it involved a second transformation, which complicates things considerably. However all attempts to skip the "Text file output" step all brought me back to where I was and gave me the dreaded
Text file output step (omitting the header, separators, and quotes), I could then successfully open and parse that file with the "Get data from XML" step (from within a second transformation).
This was of course a bit annoying since it involved a second transformation, which complicates things considerably. However all attempts to skip the "Text file output" step all brought me back to where I was and gave me the dreaded Content is not allowed in prolog. error. So something was happening to the document between saving and loading from disk that somehow fixed it.
Mind w3c validator Warnings!
I decided to investigate a bit more. What I didn't notice at first when I validated the XML document is that, despite passing validation, it does yield 2 warnings:- No DOCTYPE found! Checking XML syntax only.
- Byte-Order Mark found in UTF-8 File.
UTF-8, the BOM, and java don't play nice together
I knew what a BOM was, but I didn't quite understand it's implications in particular for java and java-based applications. Here's a quick list of things you need to know to understand the problem:- The byte-order mark (BOM) is a special unicode character that indicates several details of the encoding of an inputstream.
- The BOM is optional, and for UTF-8 it is actually disrecommended. But, apparently, this does not mean it's never there, or even non-standard!
- The particular combination of a BOM occurring in a UTF-8 stream is not supported by java. There are bug reports about it here and here.
A better workaround
We can first retrieve the document with the "Http Client" step, and then remove the BOM if it is present, and then process the document using the Get data from XML step. The transformation below illustrates that setup: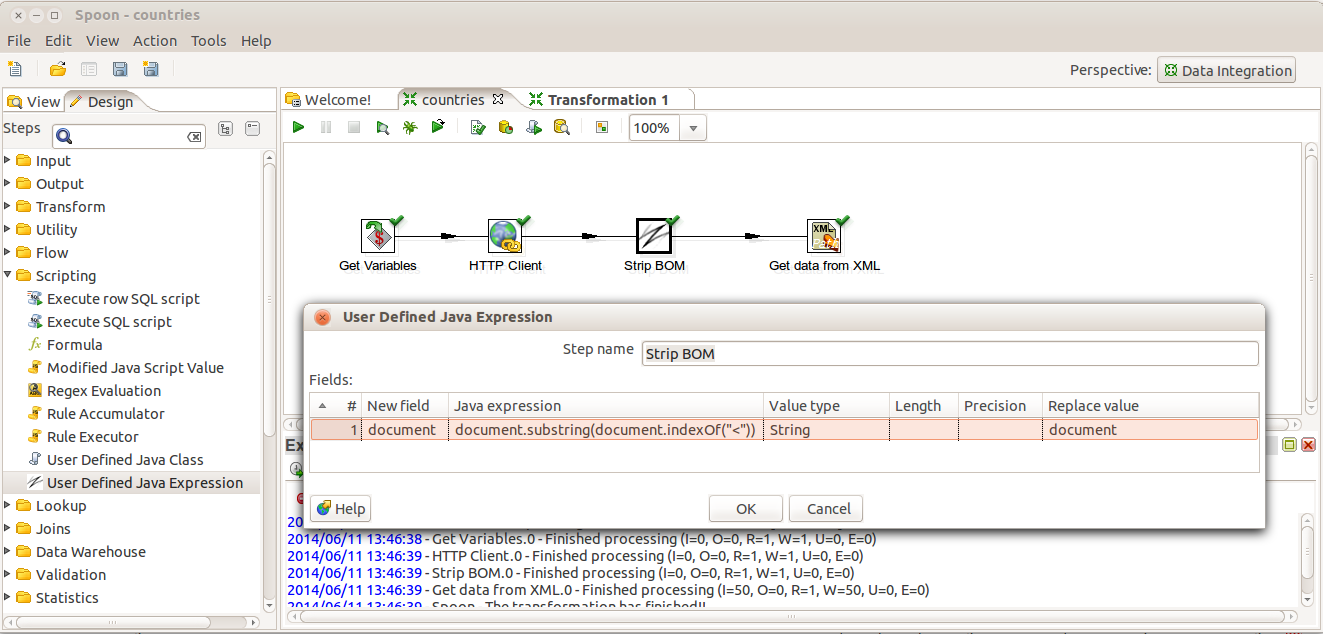 So, the "HTTP client" step retrieves the XML text in the
So, the "HTTP client" step retrieves the XML text in the document field, and the  User-defined Java Expression step simply finds the first occurrence of the less than character (<), which demarcates either the start of the xml declaration, or the document element. The code for that expression is rather straightforward:
User-defined Java Expression step simply finds the first occurrence of the less than character (<), which demarcates either the start of the xml declaration, or the document element. The code for that expression is rather straightforward:
document.substring(document.indexOf("<"))
All in all, not very pretty, but it does the job.
I hope this was of some use to you.
UPDATE1: I created PDI-12410 pertaining to this case.
UPDATE2: Apart from the BOM, there seems to be a separate, independent problem when the XML is acquired from a URL and the server uses gzip compression.
UPDATE3: I have a commit here that solves both the BOM and the gzip issues: https://github.com/rpbouman/pentaho-kettle/commit/6cf28b5e4e88022dbf356ccad01c3b949bed4731.
5 comments:
I have a similar issue. I'm using DI 4.4.2. My process reads text file with utf8 with BOM encoding. I already specifying utf8 encoding and and BOM characters are gone in preview the records, but it errors out when data gets inserted into a table. Do you think your fix would work? Thanks
Hi unknown.
Thanks for your interest.
Look, questions like "do you think your fix will work" are really not that smart - it's not like I'm trying hard to write about stuff that doesn't work.
Obviously I'm not guaranteeing anything; I simply documented what worked for me. If I were you, I'd try and see where I'd get stuck. And maybe if I'd find out something specific to your specific problem, I'd blog about that just like I have that.
So why don't you go ahead and try? I did my utmost best to explain exactly what I did. You only have to repeat and see if it works for you.
Thanks for the guide, it helped me! I had a similar issue with JSON consuming a REST API that was sending the data as application/json and UTF8 with BOM.
For fix it, I create a Java Expression with this code
response.substring(1, document.length())
And I was able to parse the JSON using JSON Input.
Hi Roland, thanks for this info. You're the ONLY person I've been able to find that has even referenced a problem with gzip web response data in-stream:
"UPDATE2: Apart from the BOM, there seems to be a separate, independent problem when the XML is acquired from a URL and the server uses gzip compression."
Unfortunately, your github commit link is broken. I'm using the "HTTP POST" step to access json data from a server that's coming back GZIPed. I know the data response from the server is good (tested by routing pdi request through Fiddler), but once it gets to Kettle it's no longer recognized as a valid gzip file. Have you had similar issues? Any suggestions?
> Unfortunately, your github commit link is broken.
I'm sorry about that.
> but once it gets to Kettle it's no longer recognized as a valid gzip file.
Not entirely sure what you mean. But have you tried to save the response to file and then tried to uncompress it?
Post a Comment